YouTube 9개 채널에서 자막 긁어와서 WordPress까지 자동 발행하는 파이프라인을 완주했어요. 처음엔 15분 걸렸는데 병렬 처리로 1분 40초까지 줄였더라고요. 근데 이게 끝이 아니었어요.
YouTube 자막 수집 자동화 첫 구현
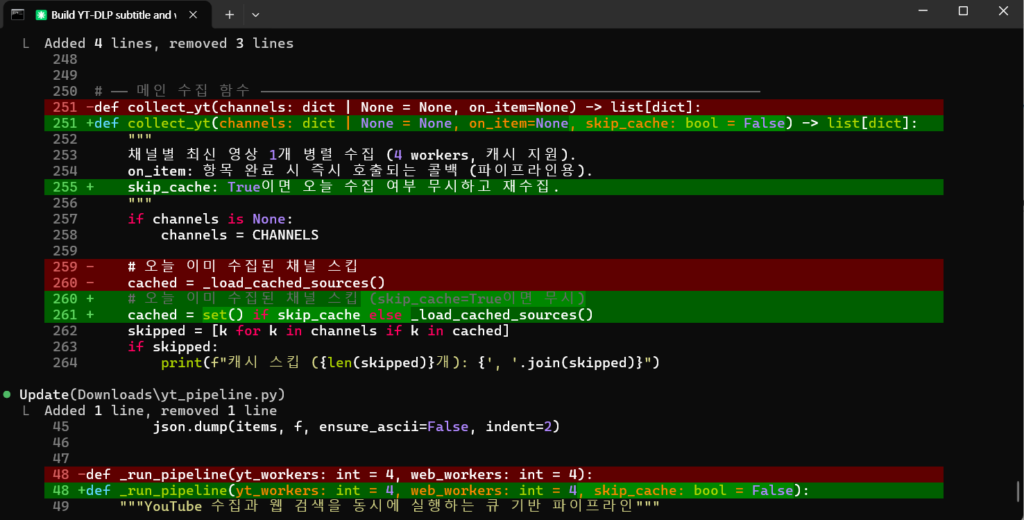
yt_collector.py라는 파일을 만들어서 YouTube 자막 수집 기능을 넣었어요. 타겟으로 잡은 채널이 9개나 됐는데요.
- Nate Herk (AI 도구 리뷰)
- Matt Wolfe (AI 뉴스)
- Fireship (개발 정보)
- 조코딩 (한국 개발자)
- AgentOS (AI 에이전트)
- Builder Josh (노코드)
- Sabrina Ramonov (AI 비즈니스)
- AI Explained (AI 연구)
- 피피티프로 (업무 자동화)
처음 돌렸을 때 15분이나 걸렸어요. 순차 처리로 채널 하나씩 접근하니까 당연히 느릴 수밖에 없었죠.
구체적인 자막 수집 과정
YouTube API를 사용해서 각 채널의 최신 영상 10개씩 가져오도록 설정했어요. 자막 추출할 때는 youtube-dl 라이브러리를 썼고, 한국어와 영어 자막을 우선적으로 수집했어요.
문제는 일부 영상에 자막이 아예 없거나 자동 생성 자막만 있는 경우였어요. 이런 경우를 위해 fallback 로직을 추가했죠. 자동 생성 자막도 품질이 나쁘지 않더라고요.
병렬 처리로 9배 속도 개선
ThreadPoolExecutor를 써서 병렬 처리로 바꿨더니 1분 40초로 줄었어요. 거의 9배 개선된 셈이죠. 캐싱 기능도 추가해서 같은 영상은 다시 안 긁어오게 했고요.
| 처리 방식 | 소요 시간 | 수집량 |
|---|---|---|
| 순차 처리 | 15분 | 9채널 |
| 병렬 처리 | 1분 40초 | 9채널 |
▲ YouTube 자막 수집 성능 개선 결과
웹 검색으로 가져온 것까지 합치니까 총 28개 항목이 수집됐어요. 이제 진짜 자동화다 싶었는데 문제는 다음 단계에서 터졌죠.
병렬 처리 구현 세부사항
처음엔 max_workers를 5로 설정했다가 YouTube API 제한에 걸려서 3으로 줄였어요. 너무 많은 동시 요청을 보내면 429 에러(Too Many Requests)가 발생하더라고요.
각 채널별로 별도의 스레드에서 실행되도록 했고, 실패한 채널은 재시도 로직을 추가했어요. 최대 3번까지 재시도하고 그래도 안 되면 로그만 남기고 넘어가도록 했죠.
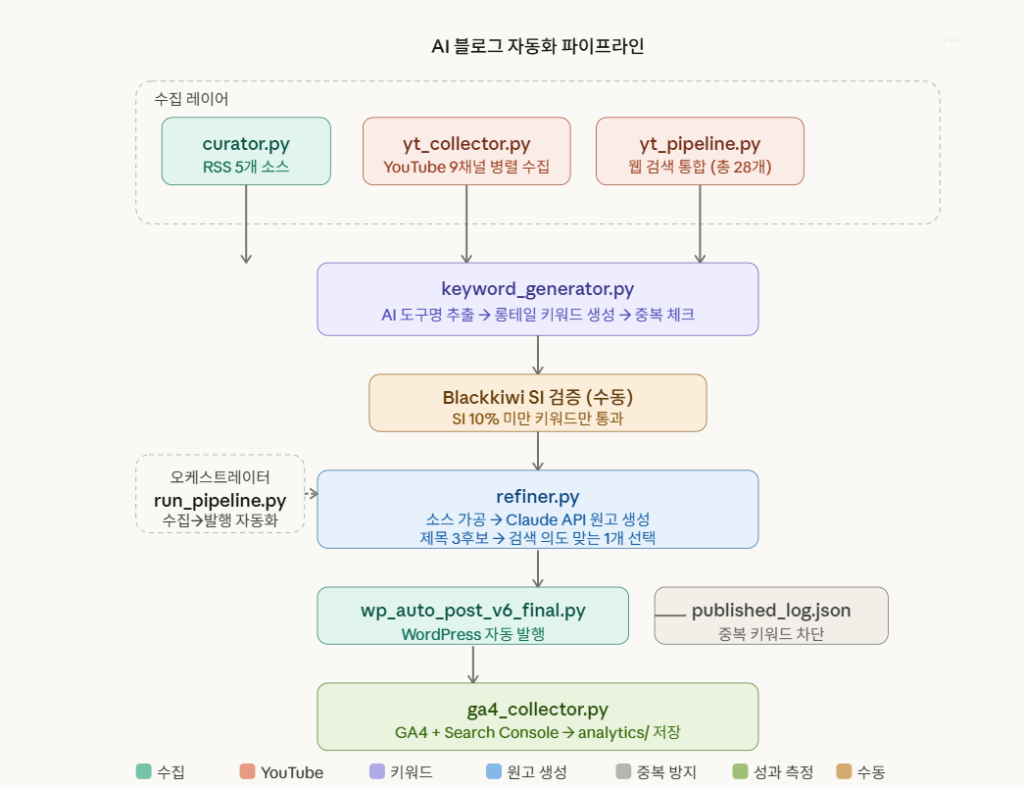
완전 자동화 파이프라인 구축 시도
run_pipeline.py라는 메인 파일을 만들어서 수집부터 발행까지 한 번에 돌리는 걸 시도했어요. 흐름은 이랬어요.
- YouTube 자막 + 웹 검색으로 소재 수집
- 키워드 선택 및 우선순위 매기기
- 선택된 키워드로 블로그 원고 생성
- WordPress에 자동 발행
첫 번째 완주는 성공했어요. 근데 결과물을 보니까 문제투성이더라고요.
파이프라인 아키텍처 설계
데이터 흐름을 설계할 때 각 단계별로 JSON 파일로 중간 결과를 저장하도록 했어요. 이렇게 하면 중간에 문제가 생겨도 처음부터 다시 돌릴 필요가 없거든요.
– collected_data.json: 수집된 원본 데이터
– processed_keywords.json: 키워드 분석 결과
– generated_articles.json: 생성된 블로그 글
– publish_log.json: 발행 결과
각 단계마다 타임스탬프와 상태 정보를 함께 저장해서 나중에 디버깅할 때 도움이 되도록 했어요.
자동화 파이프라인에서 발견된 5가지 문제
한 번에 여러 글을 돌리니까 이상한 것들이 막 나왔어요.
① 글 중간에 잘림 현상
Claude의 max_tokens이 8000으로 설정돼 있어서 긴 글이 중간에 뚝 끊어졌어요. 16000으로 늘렸더니 해결됐고요.
처음엔 이게 Claude 문제인 줄 알았는데, 토큰 계산 방식을 제대로 이해 안 하고 있었던 거더라고요. 한국어는 영어보다 토큰을 더 많이 소모하거든요. 평균적으로 한국어 1글자당 1.5토큰 정도로 계산하면 안전해요.
② SEO에 안 맞는 제목들
“AI 도구 소개”같은 뻔한 제목들이 계속 나왔어요. [숫자]+[시간]+[결과/이득] 공식으로 프롬프트를 개선했죠.
제목 생성 프롬프트를 아예 별도로 분리했어요. 먼저 키워드 분석을 하고, 그 다음에 해당 키워드에 맞는 제목 5개를 생성한 다음 그 중에서 가장 좋은 걸 선택하도록 했어요.
③ 직역된 어색한 용어
“Large Language Model”을 그대로 번역해서 “거대 언어 모델”이라고 쓰더라고요. 한국 AI 커뮤니티에서 쓰는 자연스러운 표현으로 바꾸고, 영어 원문은 괄호로 설명 추가했어요.
용어 사전을 만들어서 자주 나오는 영어 용어들의 한국어 대응을 정리했어요. 예를 들어:
- Prompt Engineering → 프롬프트 엔지니어링
- Fine-tuning → 파인튜닝
- Retrieval Augmented Generation → RAG
- Token → 토큰
④ 허위 경험담 생성
가장 심각했던 문제예요. “직접 써봤더니” 같은 거짓 경험담을 AI가 지어내더라고요. 팩트 조작 금지 규칙을 프롬프트에 강하게 넣었어요.
이 문제가 발생하는 이유는 AI가 사용자 친화적인 글을 쓰려고 하다 보니 경험담을 추가하려고 하는 경향 때문이에요. 프롬프트에 “개인 경험 언급 금지”, “팩트만 서술”, “출처 명시 필수” 같은 제약을 명확히 추가했어요.
⑤ 중복 발행 문제
같은 주제로 비슷한 글이 계속 올라가는 걸 발견했어요. published_log.json 파일을 만들어서 발행 이력을 관리하고 중복을 방지하도록 했고요.
키워드 유사도 검사 로직도 추가했어요. 새로 생성할 키워드와 기존 발행된 글의 키워드들 간 코사인 유사도를 계산해서 0.8 이상이면 스킵하도록 했어요.
테스트 방식의 중요성
한 번에 많이 돌리지 말고 1개씩 테스트했어야 했어요. 그러면 이런 문제들을 미리 잡을 수 있었을 텐데요.
| 방식 | 장점 | 단점 |
|---|---|---|
| 한 번에 대량 실행 | 빠른 결과 확인 | 문제 발생 시 대량 오류 |
| 1개씩 단계별 테스트 | 문제 조기 발견 | 시간 오래 걸림 |
▲ 자동화 테스트 방식 비교
앞으로는 1개 발행→결과 확인→문제 해결→확장 순서로 진행해야겠어요.
단위 테스트 도입
각 함수별로 단위 테스트를 만들어 두니까 문제 발생 지점을 빠르게 찾을 수 있더라고요. pytest를 사용해서 다음과 같은 테스트들을 만들었어요:
- 자막 추출 함수 테스트
- 키워드 분석 결과 검증
- 블로그 글 생성 품질 체크
- WordPress API 연결 테스트
비용 관리에서 배운 교훈
Claude Pro 요금제를 쓰고 있는데 사용량 제한이 있더라고요. 한 번에 너무 많이 돌리니까 제한에 걸려서 중간에 멈췄어요.
API 요금제로 갈아탈지 고민 중이에요. 토큰당 과금이지만 제한이 없으니까 자동화에는 더 맞을 것 같고요.
토큰 사용량 모니터링
각 단계별 토큰 소모량을 로깅하도록 했어요. 이렇게 하니까 어느 부분에서 토큰을 많이 쓰는지 파악할 수 있더라고요.
- 키워드 추출: 평균 2,500토큰
- 블로그 글 생성: 평균 12,000토큰
- 제목 및 메타데이터 생성: 평균 1,000토큰
글 1개당 평균 15,500토큰 정도 쓰더라고요. Claude API 기준으로 약 0.4달러 정도 드는 셈이에요.
점진적 개발의 중요성
처음부터 완벽한 걸 만들려고 하지 말고, 작동하는 버전부터 만든 다음에 개선하는 게 맞는 것 같아요.
- 일단 작동하는 최소 버전 구현
- 실제 사용하면서 문제점 발견
- 하나씩 개선해 나가기
- 안정화된 후 확장
버전 관리 전략
Git을 사용해서 각 개선사항마다 커밋을 남겼어요. 특히 성능 개선이나 버그 수정할 때는 before/after 비교를 커밋 메시지에 남기도록 했어요.
예를 들어: “feat: 병렬 처리 추가 (15분 → 1분 40초)” 이런 식으로요. 나중에 비슷한 프로젝트 할 때 참고하기 좋더라고요.
YouTube 자막 수집 자동화 다음 개선점
아직 개선할 게 많이 남았어요.
- 품질 필터링: 조회수나 업로드 날짜 기준으로 좋은 콘텐츠만 선별
- 키워드 중복 제거: 비슷한 주제 통합해서 더 좋은 글 만들기
- 발행 스케줄링: 하루에 1-2개씩만 올라가도록 조절
- 카테고리 자동 분류: AI 도구, 개발, 비즈니스별로 자동 분류
모니터링 대시보드 구축
Streamlit으로 간단한 대시보드를 만들어서 파이프라인 상태를 실시간으로 볼 수 있게 했어요. 여기서 볼 수 있는 정보들:
- 일별 수집 현황
- 각 채널별 성과
- 토큰 사용량 추이
- 발행된 글의 품질 점수
- 오류 발생 현황
에러 핸들링 강화
네트워크 오류나 API 제한 등 예상 가능한 에러들에 대한 처리를 추가했어요. 특히 YouTube API는 할당량 제한이 있어서 하루 사용량을 추적하고 제한에 가까워지면 경고를 보내도록 했어요.
자주 묻는 질문
Q: YouTube 자막 수집이 저작권 문제 없나요?
자막을 그대로 복사하는 게 아니라 키워드와 아이디어만 추출해서 새로운 글을 쓰는 거라 문제없어요. 원본 영상 링크도 출처로 표시하고 있고요.
Q: 병렬 처리 속도 개선이 항상 9배 빠를까요?
네트워크 상황이나 YouTube API 응답 속도에 따라 달라져요. 평균적으로는 5-7배 정도 개선되는 것 같아요.
Q: 하루에 28개 글을 다 발행하나요?
아니에요. 28개는 수집된 소재 개수고, 실제로는 그 중에서 좋은 키워드 3-4개만 선별해서 글로 만들어요.
Q: 어떤 기준으로 좋은 키워드를 선별하나요?
검색량, 경쟁도, 트렌드 지수를 종합해서 점수를 매겨요. 또한 우리 블로그와 관련성이 높은 키워드인지도 체크하고요. 이 모든 과정을 AI가 자동으로 처리해요.
Q: WordPress 자동 발행 시 어떤 정보까지 설정되나요?
제목, 본문, 메타 설명, 카테고리, 태그, 특성 이미지까지 모두 자동으로 설정돼요. SEO 플러그인(Yoast)과도 연동해서 메타 정보가 제대로 들어가도록 했고요.
향후 확장 계획
멀티 플랫폼 지원
YouTube뿐만 아니라 팟캐스트, 블로그, 뉴스 사이트까지 소스를 확장할 계획이에요. 각 플랫폼별로 적합한 수집 방법과 처리 로직을 개발하고 있어요.
AI 모델 다양화
현재는 Claude만 쓰고 있는데 GPT-4, Gemini 등 다른 모델들도 테스트해 볼 예정이에요. 모델별로 장단점이 다르니까 용도에 따라 최적의 모델을 선택할 수 있도록 하고 싶어요.
품질 평가 시스템
생성된 글의 품질을 객관적으로 평가하는 시스템을 만들고 있어요. 가독성, 정보성, SEO 점수 등을 종합해서 일정 점수 이하인 글은 자동으로 걸러내도록 할 계획이에요.
YouTube 자막 수집부터 자동 발행까지 파이프라인을 완주했지만 여전히 손봐야 할 부분이 많아요. 그래도 15분에서 1분 40초로 줄인 건 확실한 성과죠. 다음엔 품질 필터링에 집중해 볼 예정이에요.
썸네일 사진: Arthur Lambillotte on Unsplash